BibSpire anbefalinger
BibSpire er et automatisk litteratur-anbefalingssystem med intergration i bibliotekshjemmesider, som jeg fandt på og udviklede i 2019:
- I løbet af det første år fik jeg systemet i drift eller solgt til ca. 20% af de danske biblioteker (nogle direkte og andre via leverandører).
- Anbefalingerne havde stor målbar effekt på brugen af bibliotekshjemmesiderne.
- Anbefalingerne kunne ikke rulles ud til størstedelen af bibliotekerne ("redaktørbibliotekerne"), pga. ledelsesmæssige beslutninger i DDB/ITK, vistnok relateret til de ville i gang med nyudvikling af et nyt tredje anbefalingssystem fra grunden af, (der i dag kan ses i appen). Derfor solgte jeg i 2020 anbefalingssystemet til DBC.
- Den daværende anbefalingsalgoritme er nu integreret DBCs FBI-anbefalingssystem, som bruges i bibliotek.dk og i Next.
- DBC har ikke migreret DDB-CMS anbefalingskomponenten og dens APIer, som derfor stadigt ligger på min server, og jeg står for driften af.
- Jeg har flere forbedringer til anbefalingssystemet, men de seneste år har jeg ikke haft resourcer til at udvikle videre på det.
- Crowdfunding af mine biblioteksprojekter, vil kunne sætte gang i udviklingen.
Herunder er historiske eksempler på anbefalinger, dokumentation etc.
Om BibSpire (Beskrivelse fra 2020).
BibSpire er anbefalinger, der bliver i vist DDB-CMS ved materialevisning, værkvisning og lånerstatus. Anbefalingerne har medført mere end 250.000 ekstra materialevisninger i DDB-CMS.
BibSpire-anbefalingerne medfører en mærkbar stigning i bibliotekernes udlån.
Bibliotekerne siger:
"Og vi kan se effekten. I september har vi haft en 16% stigning i antal reserveringer via hjemmesiden her på Randers Bibliotek."
"Den er også helt genial at bruge på vagter, hvis man selv løber tør for anbefalinger eller hvis man ekspederer målgrupper der læser litteratur man ikke selv kender så godt."
"Ser godt ud. Enkelt at bruge og overskueligt."
"Ja- jeg er sgu også imponeret over hvor meget mere trafik vi får. Det gamle [personalisering] modul gav på en uge ca 60 klik og 16 reserveringer. På en uge har Bibspire givet 600 klik og næsten 100 reserveringer."
"Kæmpe thumbs-up herfra. Recommenderen fungerer helt fantastisk."
"... vi kan KUN sige at anbefalingsmodul virker og vores bruger er glæde for den, det kan ses i vores reserverings statistik."
Anbefalingerne bruges i DDB-CMS i mere end 20 kommuner og har kørt i drift siden juni 2019. Eksempel kan ses på bib.ballerup.dk, silkeborgbib.dk og aalborgbibliotekerne.dk (scroll ned til afsnittet “Inspiration”, som indeholder anbefalingerne).
BibSpire er den bedste digitale anbefalingsløsning til bibliotekerne, – trods flere millionprojekter i bibliotekssektoren (ADHL, Personalisering, PAPPS) med samme formål..
Vil I gerne have flere udlån? Så tilføj BibSpire-anbefalingerne til jeres DDB-CMS i dag! Se hvordan under "Tilføj anbefalingerne til dit DDB-CMS".
Om projektet
BibSpire-anbefalingerne er skabt af Rasmus Erik, en selvstændig opensource softwareudvikler med mange år tilknytning til bibliotekssektoren. Jeg byggede BibSpire-anbefalingerne for egen regning fordi jeg brænder for det og kan se at er til gavn. Se også beskrivelsen af mine andre projekter i bibliotekssektoren under solsort.dk/biblioteker.
Jeg har kodet på egne biblioteks-anbefalinger siden 2014. Anbefalingerne har blandt andet har været brugt i pris-vindende inspirations-app og linked-data eksperimenter/prototyper. I 2018 blev jeg opfordret til at lave en komponent til DDB-CMS, som har kørt i produktion på bibliotekshjemmesider siden juni 2019. I 2020 bliver BibSpire's anbefalinger integreret i DBCs anbefalingsløsning, så de ikke længere hænger på en enkeltperson, men bliver en del af den større infrastuktur.
Anbefalingssystemer ultimo 2020
For 1½ år siden udviklede jeg en anbefalingsvisning til bibliotekernes hjemmesider, og fik den i drift på 22 ud af ca. 50 ikke-redaktørbiblioteker. DDB/DDF ønsker ikke at gøre den tilgængelig for redaktørbibliotekerne(ca. 50% af bibliotekerne).
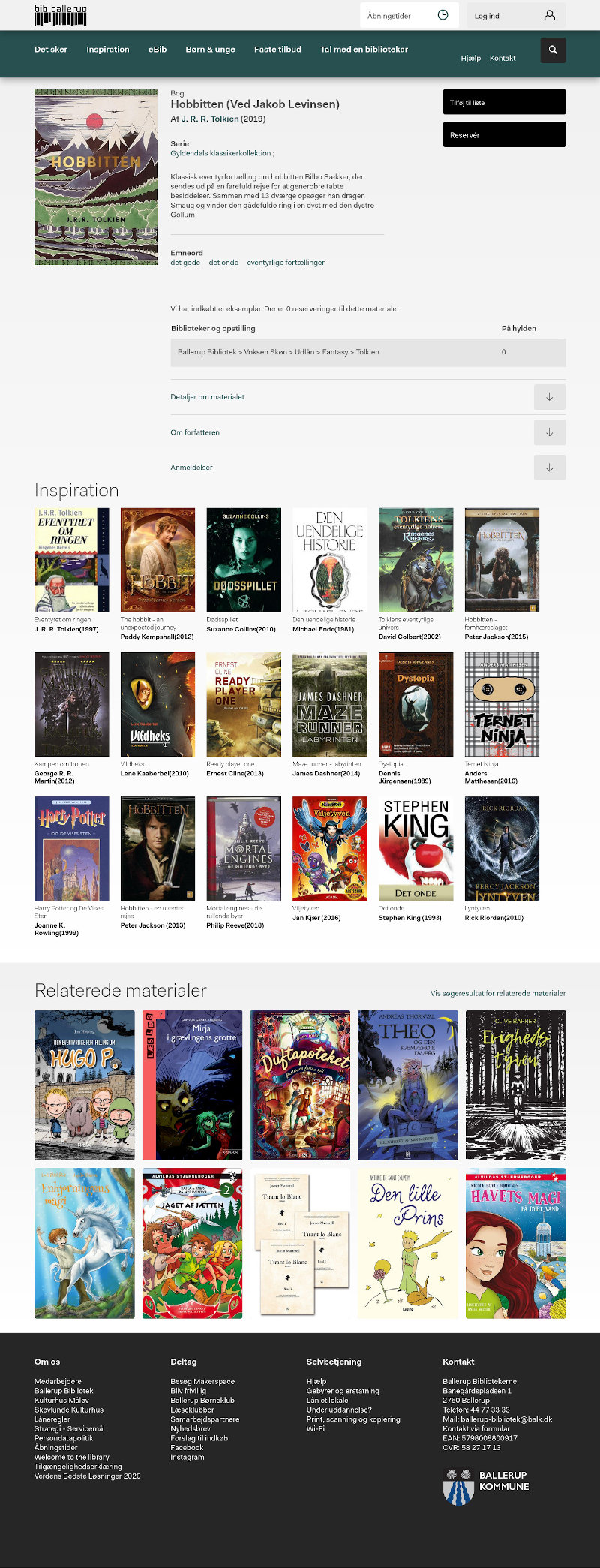
Forøjeblikket vises begge anbefalingsvisninger på Ballerup Bibliotek under "Inspiration"(min løsning) og "Relaterede materialer"(DDFs løsning) – billeder siger mere end ord:
Ballerup: Hobbitten
Ballerup: Den Lille Prins
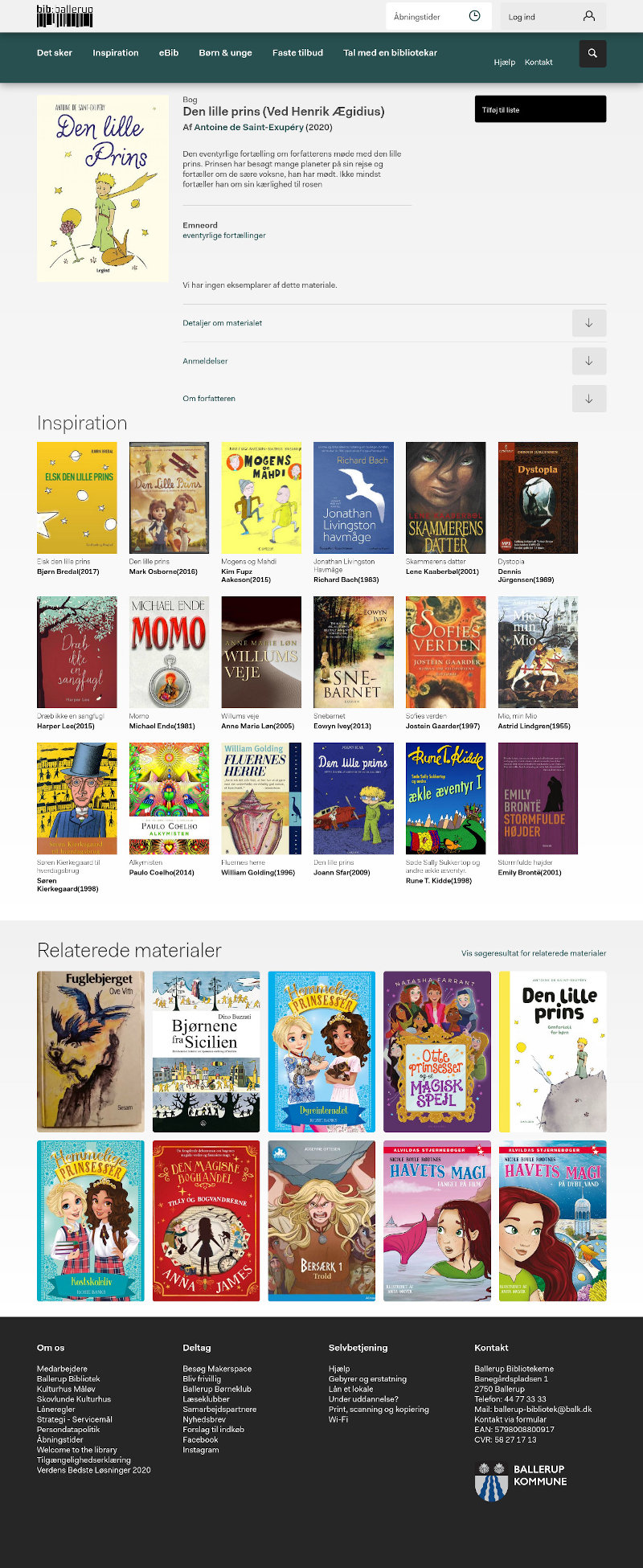
Klik på billederne herover for at åbne siden og selv gå på opdagelse.
I ovenstående "Relaterede materialer" for Hobbitten, klikkede jeg på på "Den Lille Prins", og fik et materiale, der ikke fandtes i bibliotekets beholdning, – dette ser ud til at ske jævnligt.
Sammenligning
Her er en sammenligning d. 2020-12-05 af anbefalingerne fra BibSpire, "Relaterede materialer" og PAPPS.
Anbefalingerne undersøges ved stikprøve af det 1, 10, 100, 1000 og 10.000 mest populære materiale på Ballerup Bilioteks hjemmeside. Dette sikrer, at vi både ser anbefalinger for populære og long-tail materialer. Materialerne er udvalgt systematisk – før end jeg kender anbefalingerne – for at undgå bias.
1. mest populære870970-basis:47109353 (884 visninger)
Hvor flodkrebsene synger Af Delia Owens (2019)10. mest populære870970-basis:47678633 (500 visninger)
Satans sommer : krimi Af Kim Faber (2020)100. mest populære870970-basis:48152392 (154 visninger)
Jeg tog ned til bror : roman Af Karin Smirnoff (f. 1964) (2020)1.000. mest populære870970-basis:46764617 (44 visninger)
Verdens vildeste børn Af David Pepe Birch (2019)10.000. mest populære870970-basis:52736730 (10 visninger)
Angst, grænser og rum : om angstens ressourcer og nødvendighed Af Lise Winther-Jensen (2016)
Stikprøven er taget som de første 10 anbefalinger under henholdsvist "Inspiration" og "Relaterede materialer" på Ballerup Biblioteks hjemmeside og "Noget de ligner (beta)" i Biblioteket-appen (logget ind via Ballerup).
Resultatet kan ses herunder.
Hvor flodkrebsene synger Af Delia Owens (2019):
| BibSpire "Inspiration" |
DDB-CMS "Relaterede materialer" |
PAPPS |
1. _Sara Omar:_ Skyggedanseren |
1. _Louise Winther:_ Men så døde mormor |
1. _Tonny Munnecke:_ Dreng af tid og sted |
|---|
Satans sommer Af Kim Faber:
| BibSpire "Inspiration" |
DDB-CMS "Relaterede materialer" |
PAPPS |
1. _Anna Grue:_ Mysteriet i Genbrugsen |
1. _Mari Jungstedt:_ Et mørke iblandt os _Heraf 8 materialer der ikke findes på Ballerup Bibliotek_ |
1. _S. J. Bolton:_ Rødt lys stop |
|---|
Jeg tog ned til bror Af Karin Smirnoff:
| BibSpire "Inspiration" |
DDB-CMS "Relaterede materialer" |
PAPPS |
1. _Ocean Vuong:_ Vi er kortvarigt smukke her på jorden |
1. _Louise Winther:_ Men så døde mormor _Heraf 3 materialer der ikke findes på Ballerup Bibliotek_ |
Ingen anbefalinger. |
|---|
Verdens vildeste børn Af David Pepe Birch (2019):
| BibSpire "Inspiration" |
DDB-CMS "Relaterede materialer" |
PAPPS |
1. _Merete van den Berg:_ 107 danske Pippi-piger |
1. _Frida Bejder Klausen:_ Sådan bruger du TikTok Heraf 4 materialer der ikke findes på Ballerup Biblioteket. |
1. _Sebastian Klein:_ Verdens 100 vildeste dyr |
|---|
Angst, grænser og rum – om angstens ressourcer og nødvendighed Af Lise Winther-Jensen:
| BibSpire "Inspiration" |
DDB-CMS "Relaterede materialer" |
PAPPS |
1. _Mikkel Arendt:_ Kort & godt om angst |
1. _Leïla Slimani:_ Adéle _Heraf 1 materiale der ikke findes på Ballerup Bibliotek_ |
1. _Jens Henrik Thomsen:_ Slip mig fri! – guide til børn og unge med separationsangst (kun 2 anbefalinger) |
|---|
Jeg må overlade subjektive vurderingen af kvaliteten af anbefalingerne til læseren, – da jeg jo har udviklet den ene af løsningerne.
Anbefalingssystemer
I slutningen af 2020 har jeg kendskab til følgende anbefalingssystemer:
- BibSpire, som jeg har udviklet.
- Eksempel: https://bib.ballerup.dk/ting/object/870970-basis%3A46652681 se under "Inspiration"
- Anbefalingsvisning: React komponent indlejret i DDB-CMS
- Anbefalingsmotor: Kombinerer webstatistik, udlånsstatistik og metadata.
- Ejerskab: Løsningen er 100% opensource. BibSpire som produkt drives nu af DBC.
- PAPPS
- Eksempel: Findes i app'en Biblioteket under "Noget der ligner (beta)"
- Anbefalingsvisning: del af app'en
- Anbefalingsmotor: Proprietær, – Redia blokerer direkte for deling af viden, – her er eksempler på censorerede dokumenter som jeg fik, da jeg bad ITK om indsigt i løsningen: PAPPS Projektbeskrivelse og PAPPS Faseplan.
- Ejerskab: Løsning ejes af kommerciel virksomhed, der kun giver bibliotekerne begrænset brugsret – eksempelvis kan bibliotekerne ikke lave et opensource samarbejde i stil med TING-communitiet, da licensen for PAPPS indeholder opensource-inkompatible klausuler. Dette til trods for at den er offentligt finansieret.
- Læsekompasset
- Eksempel: https://laesekompas.dk/find?tags=870970-basis%3A46652681 klik på "Minder om"
- Anbefalingsvisning: Både separat site, og React komponent indlejret i DDB-CMS
- Anbefalingsmotor: Indeholder berigede læsekompasdata mm. – jeg kender ikke detaljerne? Mine erfaringer fra BibSpire overføres hertil og videreudvikles her. Dette bliver sandsynligvis det bedste anbefalingssystem på langt sigt.
- Ejerskab: Løsningen ejes af DBC der ejes af KL(Kommunerne)
- DDB-CMS "Relaterede materialer"
- Eksempel: https://bib.ballerup.dk/ting/object/870970-basis%3A46652681 se under "Relaterede materialer"
- Anbefalingsvisning: React komponent indlejret i DDB-CMS
- Anbefalingsmotor: Søgning i brønden efter nøgleord.
- Ejerskab: Løsningen ser ud til at være opensource.
- bibliotek.dk og Den Åbne Platform
- Eksempel: https://bibliotek.dk/da/work/870970-basis%3A46652681 se under "Måske er du også interessert i"
- Anbefalingsvisning: Del af bibliotek.dk-sitet. Kan også tilgås af andre løsninger via den åbne platform.
- Anbefalingsmotor: "[...] bruger flere typer data: Ud over udlånsdata inddrager den anonymiseret data om, hvordan der søges på bibliotek.dk, og metadata om materialerne bliver brugt på nye måder, samtidig med at nye typer af metadata er i spil – fx metadata om stemning mv. fra Læsekompasset". Kilde: DBC
- Ejerskab: Løsningen er en del af FBI og styres af Kombit.
- Odense/Fyn: "Andre med samme søgning lånte også"
- Eksempel: https://www.odensebib.dk/ting/object/870970-basis%3A46652681 se under "Andre med samme søgning lånte også"
- Anbefalingsvisning: Sandsynligvis del af fyn-bibliotekerne DDB-CMS-branch.
- Anbefalingsmotor: ¿Måske baseret på webstatikstik – jeg kender ikke detaljerne?
- Ejerskab: Løsningen er svjv. udviklet af Odense og muligvis er den opensource?
- Herning: "Noget der ligner Titel-på-materiale"
- Eksempel: https://www.herningbib.dk/ting/object/870970-basis%3A29720207
- Anbefalingsvisning: Sandsylingvis del af Hernings DDB-CMS-branch
- Anbefalingsmotor: Recommenderen gør tre ting: 1) relaterede materialer ud fra Opstilling, emneord, kategori (børne/voksen), materialetype og sprog., 2) mere af samme forfatter og 3) andre materialer i samme serie.
- Ejerskab: Løsningen er udviklet af Herning
Tilføj anbefalingerne til dit DDB-CMS
Hvis du selv kan tilføje moduler til DDB-CMS, så kan du let installere BibSpire-anbefalingerne ved at følge denne vejledning.
Ellers kan din leverandør gøre det for dig, – giv dem blot et link til denne side.
Har du spørgsmål undervejs, så er du meget velkommen til at skrive/ringe.
Sådan tilføjer du anbefalinger til DDB-CMS
Der er to forskellige måder at tilføje anbefalingerne til DDB-CMS. Enten kan man bruge “Add To Head”-drupal modulet, eller man kan bruge “ting_recommender” fra Randers Bibliotek.
Hvis man vil tilføje anbefalingerne via “Add To Head”-drupal modulet, skal man konfigurere dette, så det inkluderer <script async src="https://cdn.bibspire.dk/ddbcms.js"></script> under head.
Hvis man vil bruge ting_recommender-modulet, kan dette hentes fra https://github.com/arni/ting_recommender. Tak til Randers Bibliotek for at udvikle dette.
Når I har hentet, installeret og aktiveret modulet ting_recommender, så skal I derudover ind på /admin/structure/pages/edit/ting_object . Her skal I klikke på “Rediger indhold”. I det nye vindue skal I klikke på tandhjulet lige under overskriften Attachment 1 of 1. Klik “tilføj indhold” – > Ting og vælg Ting Recommender. Til sidst kan/skal i deaktivere “Ting Serendipitet med TingObject”. (Tak til Silkeborg bibliotek for denne uddybede beskrivelse og screenshot).